At 9:14 on a Tuesday morning, a paralegal opens the Wayback Machine to prove what a vendor's refund policy said on the day her client signed the contract. She finds one faded dot from three months earlier and nothing after it. The crawler simply never visited that page that week, and no amount of clicking will summon a snapshot that does not exist.
That gap is the whole problem with leaning on a public, best-effort archive for serious work. The Wayback Machine has preserved more than a trillion pages since 1996, and for seeing what a homepage looked like in 2003 it is exactly the right tool. But "best effort, on our schedule, for whatever we crawled" is not the same as "this page, captured when I needed it, in a form I can verify later."
For legal teams preserving evidence, compliance officers documenting regulatory pages, and competitive intelligence teams watching rivals, you need archives you control, on a schedule you set. This guide compares seven alternatives so you can match the tool to how you use web archives.
Why isn't the Wayback Machine enough for professional archiving?
The Wayback Machine is a passive, public, best-effort archive. It crawls popular sites on its own unpredictable schedule, skips pages blocked by robots.txt, never alerts you when content changes, and gives you no side-by-side diffs. For evidence, compliance, or competitive work you need captures on your schedule, that you own and can verify after the fact.
The specific gaps for professional work:
- Unpredictable capture frequency: crawlers prioritize popular sites, so a niche government page or competitor pricing page may be captured every few months, or never, and you cannot request a capture at a specific time
- No change alerts: snapshots are taken silently, so a quiet edit only surfaces when you manually recheck, possibly weeks later
- robots.txt holes and takedowns: sites can block the crawler, and organizations can retroactively pull archived content, so an archive you do not control can shrink without warning
- No diff or comparison: comparing two snapshots means loading each one and scanning by eye, with no highlighted changes
There is also the chain-of-custody problem. Courts have accepted Wayback Machine screenshots, but a third party took the capture, on an unknown schedule, with no guarantee it is complete or untampered. Stronger records mean first-party captures with timestamps, screenshots, and demonstrable integrity: the difference between "a screenshot exists somewhere" and an audit-ready web evidence capture you can stand behind. For formats, fidelity, and retention basics, see our website archiving guide.
What should a web archiving tool actually do?
The right tool depends on whether you need a one-off snapshot or an ongoing, defensible record. These capabilities separate a passive snapshot service from a system you can rely on in an audit, a lawsuit, or a competitive review.
- Scheduled captures: pages checked on a frequency you set, not random crawl timing
- Change detection: automatic identification of what differs between captures
- Diffs: side-by-side comparison with highlighted additions and removals
- Screenshots: the page as rendered, not just raw markup
- Notifications: alerts via email, Slack, Telegram, Teams, or webhooks
- Open archive format: standards such as WACZ used by libraries, governments, and legal teams
- Verifiable integrity: cryptographic hashing so each capture is tamper-evident
Which Wayback Machine alternatives are worth using?
Seven tools cover the realistic options: Archive.today and SingleFile for quick one-off snapshots, ArchiveWeb.page for manual WACZ captures, HTTrack for offline copies, Stillio for scheduled screenshots, ChangeDetection.io for self-hosted monitoring, and PageCrawl for continuous, verifiable archiving with change alerts, all compared in detail below.
PageCrawl
PageCrawl is the strongest "continuous archiving plus change tracking" alternative because it does the whole job in one place. Every check archives the page on your schedule, keeps a private history no third party can shrink, and alerts you with a clear diff when the next check detects a change. Every plan keeps screenshots and change history for each monitored page, and on higher plans you can ask us to enable complete WACZ web archives of each capture.
It is built for the people who search the Wayback Machine and come up short: legal, compliance, and competitive teams who need first-party evidence they control, captured on their own schedule.
Key archiving features:
- Complete WACZ web archives, a capability you can ask us to enable on higher plans, capturing each enabled page on every detected change in the open WACZ format
- Full-page screenshots on every check, building a visual timeline of the page
- Text diffs with highlighted additions and removals
- AI summaries that describe a change in plain language (for example, "return window changed from 30 days to 14 days")
- Notifications by email, Slack, Discord, Telegram, Microsoft Teams, and webhooks
- Full rendering, so script-heavy pages archive the way a visitor would see them, plus PDF and document monitoring
History retention: Free retains 90 days, Standard 1 year, and Enterprise and Ultimate retain history indefinitely, which matters when you must prove what a page said 18 months ago.
Best for: teams that need archiving and active monitoring together, including competitive intelligence, compliance documentation, and legal evidence preservation.
Pricing: Free plan available. Paid plans from $8 per month. Complete WACZ archiving is a capability you can ask us to enable on higher plans.
Archive.today
Archive.today (also known as archive.ph and archive.is) is a free service that snapshots any URL on demand, and it ignores robots.txt, so it can capture pages the Wayback Machine cannot. The catch: it is manual only, with no API, and captures are flat with no archive package to download.
Best for: one-off preservation and capturing content that may be removed. Pricing: free.
Stillio
Stillio takes scheduled screenshots on daily, weekly, or custom intervals and stores them in cloud galleries, with export to Google Drive, Dropbox, or S3. It is a screenshot scheduler, not a monitoring tool. If a flat image is all you need, our guide to turning a webpage into a PDF covers cheaper one-off options.
Best for: brand and design tracking where visual proof of page state is enough. Pricing: from $29 per month.
ArchiveWeb.page (Webrecorder)
ArchiveWeb.page, from the Webrecorder project that created the WACZ format, makes high-fidelity captures by recording pages interactively as you browse, including dynamic content, and saves directly to WACZ as a browser extension or desktop app. The tradeoff is that every page is captured by hand. (Webrecorder's hosted Conifer service wound down in 2026; ArchiveWeb.page and the Browsertrix crawler are the maintained tools.)
Best for: archivists and researchers who need pixel-faithful, WACZ-native captures and are happy to drive each one manually. Pricing: free (open source).
HTTrack
HTTrack is a free, open-source utility that downloads an entire website to your computer, following links and recreating the structure for offline browsing. It is download-only and does not handle script-rendered content.
Best for: making full offline copies of documentation or sites that might disappear. Pricing: free (open source).
SingleFile
SingleFile is a browser extension that saves a complete page, including CSS, images, and fonts, into one self-contained HTML file exactly as your browser rendered it. It is manual and one page at a time, so it does not scale to dozens of pages.
Best for: quickly saving individual pages for reference or evidence. Pricing: free (open source).
ChangeDetection.io
ChangeDetection.io is an open-source change detection tool with text diffs, CSS and XPath selectors, and email, Slack, and Discord notifications. The open-source version is self-hosted (you run the Docker server yourself), and there is no screenshot-based archiving on the self-hosted free tier. For a side-by-side breakdown, see our ChangeDetection.io vs PageCrawl comparison.
Best for: technical users who want full control of their infrastructure. Pricing: free (self-hosted), or managed cloud from $8.99 per month.
How do the alternatives compare?
The pattern is clear: snapshot tools capture but do not watch or verify, monitoring tools watch but rarely produce a real archive, and only one option combines scheduled captures, change alerts, and verifiable WACZ archives.
| Feature | Wayback Machine | PageCrawl | Archive.today | Stillio | ArchiveWeb.page | HTTrack | SingleFile | ChangeDetection.io |
|---|---|---|---|---|---|---|---|---|
| Scheduled captures | No | Yes | No | Yes | No | No | No | Yes |
| Change detection | No | Yes | No | No | No | No | No | Yes |
| Text diffs | No | Yes | No | No | No | No | No | Yes |
| Screenshots | No | Yes | No | Yes | Yes | No | No | Limited |
| WACZ web archives | No | On request (higher plans) | No | No | WACZ (manual) | No | No | No |
| Tamper-evident verification | No | On request (higher plans) | No | No | No | No | No | No |
| Interactive replay | Yes | Yes | No | No | Yes | No | No | No |
| Browse by date (calendar) | Yes | Yes | No | Limited | No | No | No | No |
| Notifications | No | Yes | No | No | No | No | No | Yes |
| History retention | Best effort | 90 days to indefinite | Indefinite | Plan-based | Local | Local | Local | Self-managed |
Which Wayback Machine alternative should you use?
Match the tool to the job. For a quick one-off snapshot, use Archive.today or SingleFile. For high-fidelity manual WACZ captures, use ArchiveWeb.page. For offline copies of whole sites, use HTTrack. If you need scheduled captures, change alerts, and a verifiable history you control, PageCrawl is the strongest fit.
- Legal evidence: PageCrawl for first-party, timestamped captures with screenshots and diffs (WACZ archives available on higher plans); SingleFile for a quick manual save
- Compliance and regulated retention: PageCrawl, with scheduled checks, long retention, and an auditable review trail
- Personal archiving: Archive.today for pages that might disappear, SingleFile or HTTrack for local copies
- Monitoring changes over time: PageCrawl or ChangeDetection.io for diffs and notifications; PageCrawl adds screenshots and change history on every plan
Can PageCrawl actually create a real archive, not just a screenshot?
Yes. Complete WACZ web archives are a capability you can ask us to enable on higher plans, while every plan keeps screenshots and change history for each monitored page. Once enabled, PageCrawl saves each captured page as an audit-ready archive in the open WACZ standard format, not a flat image: the full page (HTML and page resources), a screenshot, and any linked PDFs, sealed with cryptographic hashes so the capture's integrity can be verified later.
That self-contained, verifiable package is what makes PageCrawl a genuine Wayback Machine alternative rather than a screenshot service. You can browse each capture in a replay viewer and navigate the page as it stood at that timestamp, and the hashes let anyone confirm the bytes have not changed since capture.
Those two traits are why these archives hold up as audit-ready, court-admissible records. Financial firms under SEC Rule 17a-4 and life-sciences teams under FDA 21 CFR Part 11 need records preserved in a non-rewritable, verifiable form, exactly what a hashed WACZ capture provides. See our guide to SEC 17a-4 web archive monitoring for the requirements, and our piece on visual evidence in domain disputes for how first-party captures play out in adversarial settings.
How do you view how a page looked on a specific date?
Open a monitored page, pick a date on the calendar, and PageCrawl shows how the page looked on its nearest capture on or before that day. It is the Wayback Machine's date-scrubbing experience applied to your own scheduled captures, so the days you care about are actually there instead of one faded dot from months earlier.

The calendar marks every day that has a capture, so you scrub to a specific version instead of guessing. Days with complete WACZ archiving open in an interactive replay you can click through as the page stood at that timestamp; on every plan, each day shows the full-page screenshot from that capture. Because captures run on the schedule you set, a date with no capture of its own resolves to the most recent one before it, so you always see what the page actually showed as of that day. For a full walkthrough, see how to see what a web page looked like on any past date.
How do you keep on top of what your archives capture?
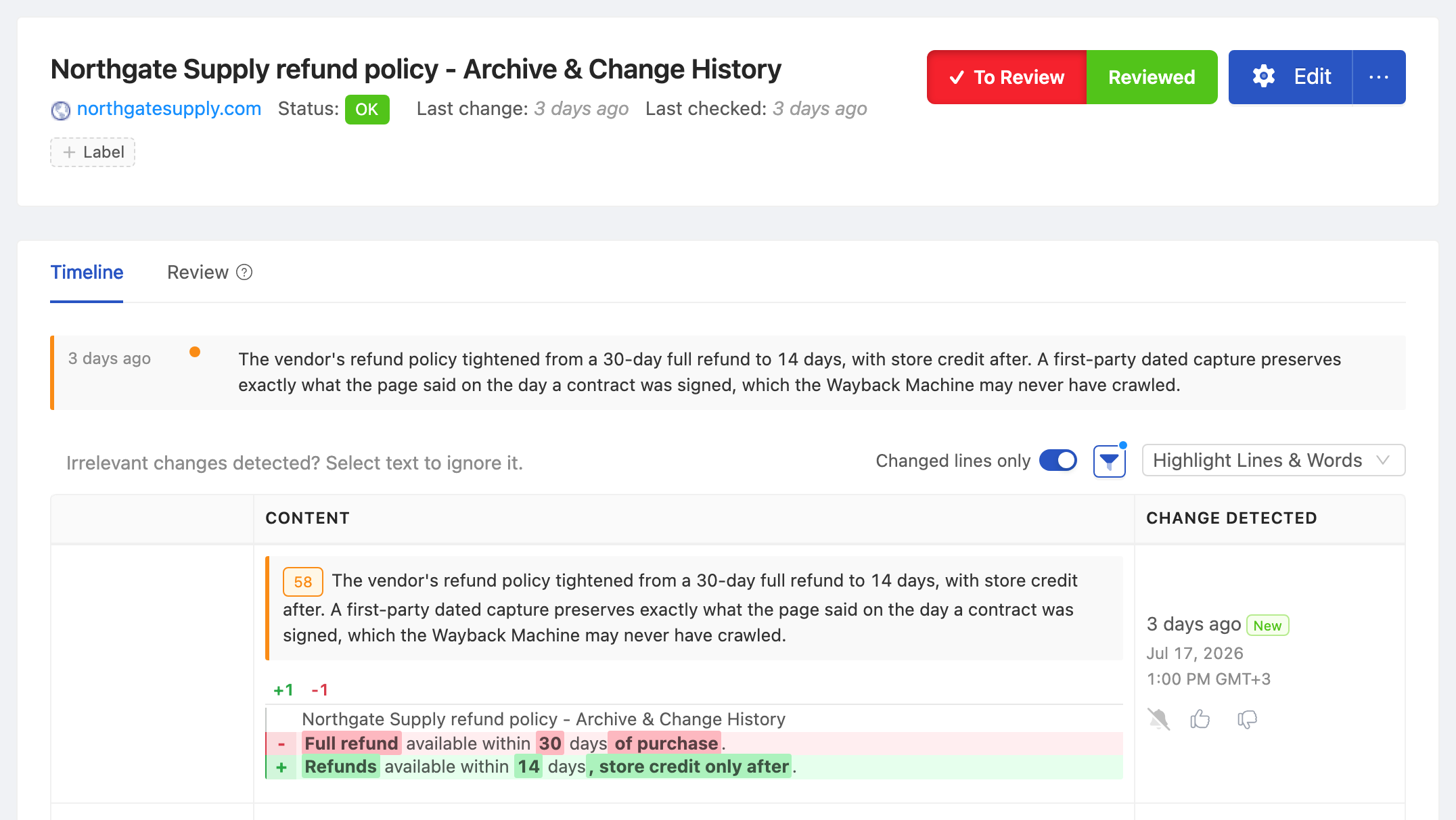
Capturing a page is only half the job. Once you are archiving dozens of vendor pages, competitor sites, and regulatory sources, you need to triage what actually changed and prove you looked at it. PageCrawl turns every detected change into a card on a Kanban-style review board: move each one from "To Review" to "Needs Attention" or "Reviewed", read the plain-language summary, add notes, and keep an auditable record of who signed off on what.

Each card carries the page name, a summary of what changed, a priority score, and how often the page has moved. That review trail is what auditors and legal teams ask for: not just that a page was archived, but that a person reviewed the change and recorded a decision.
When should you still use the Wayback Machine?
The Wayback Machine remains the right tool when you need to look backward at content you never archived yourself: historical research, verifying public claims about what a page said years ago, browsing the broad history of the web, and free, no-account submission of a URL into the public record.
If you are reconstructing the past rather than guarding the present, start there. Reach for an alternative when you need:
- Guaranteed frequency: specific pages captured at intervals you define
- Timely alerts: finding out when the next scheduled check detects a change, instead of weeks later
- Compliance records: timestamped, verifiable captures with audit trails
- Evidence you control: first-party captures with screenshots and diffs
- Competitive intelligence: tracking rivals and understanding exactly what changed and when
- Policy tracking: documenting edits to terms of service and privacy policies over time
How do you set up continuous web archiving with PageCrawl?
Setting up continuous archiving takes about ten minutes. You add the pages, turn on screenshots (and WACZ archiving, if enabled for your account), choose how often each page is checked, and decide where alerts go. After that it runs itself: every check captures the page, and every change lands in a history you control with a diff.
Our guide to monitoring website changes covers the full workflow, but here are the steps.
Step 1: Add your pages. Enter the URLs you want to archive and pick the tracking mode that fits each one: fullpage for complete captures, reader mode for article and policy text, or price mode for product pages.
Step 2: Enable screenshots and WACZ archiving. Turn on screenshot capture for every monitor to build a visual timeline. If complete WACZ archiving is enabled for your account (ask us on higher plans), turn it on for the pages that need defensible records; each detected change then produces a self-contained, hash-verified archive you can replay or download.
Step 3: Set your check frequency. Critical pages (competitor pricing, regulatory announcements) might warrant checks every 15 or 30 minutes; stable pages might only need a daily check.
Step 4: Configure notifications. Route alerts to email for a written record, plus Slack or Telegram for quick team visibility. You can mix channels per monitor, including Discord, Microsoft Teams, and webhooks.
Step 5: Review your archive. Every captured version is stored with a timestamp. Browse any page's history, open screenshots from any point, compare versions with highlighted diffs, and (where enabled) replay or export the verifiable WACZ archive.
Which PageCrawl plan do you need?
Start on the Free plan, which checks pages hourly, to validate the approach on your most critical pages. Move up when you need more pages, more frequent checks, or longer retention: Standard suits small teams, while Enterprise and Ultimate add indefinite history and checks as often as every 2 minutes.
| Plan | Price | Pages | Frequency |
|---|---|---|---|
| Standard | $8/mo or $80/yr | 100 | every 15 min |
| Enterprise | $30/mo or $300/yr | 500 | every 5 min |
| Ultimate | $99/mo or $999/yr | 1,000 | every 2 min |
Annual billing saves two months across every paid tier. Need more than 1,000 pages? Higher tiers scale up to 10,000 pages, all self-serve, no sales call or service agreement required.
How do you get started?
Start with the pages you have needed to look up before and found missing or out of date: a competitor's pricing page, a vendor's terms of service, a regulatory announcement. Add 3 to 5 of them on the Free plan with screenshots and fullpage tracking, run them for two weeks, and review the captured history. You will see how often those pages move and how much sooner you would have known.
PageCrawl is the only option here that captures on your schedule, keeps a private history you control, and tells you what changed when the next check runs. Once you have proven the approach, ask us to enable complete WACZ archives on a higher plan for the pages that need defensible, court-admissible records. Start free today, then scale to verifiable archiving once a page matters enough to prove.