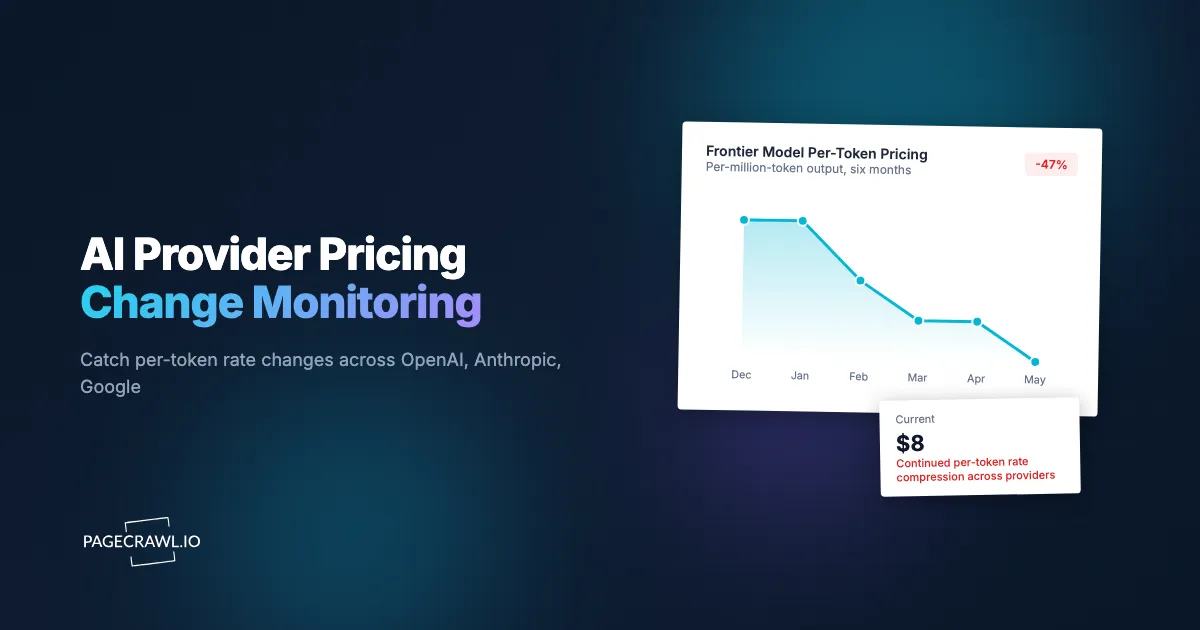
Between mid-2023 and mid-2025, the per-token price of frontier-class language models dropped by roughly an order of magnitude. Most of those cuts arrived as a quiet pricing-page update first, with a blog post or developer-portal announcement landing hours or days later. Teams running production AI workloads who watched the pricing pages directly captured a string of cost reductions on their own schedule. Teams that found out through email or developer newsletters were renegotiating volume commits and routing decisions a week behind.
LLM API pricing has dropped by an order of magnitude in two years, and the cuts often arrive without an email. For teams running production AI workloads, every per-token price change directly affects unit economics. New model tiers, batch-mode discounts, cache pricing, free-tier adjustments, and context-window pricing all change with regularity and material impact. The OpenAI, Anthropic, Google, AWS Bedrock, and Azure OpenAI pricing pages are the authoritative sources. None of them push notifications.
This guide covers how the major AI providers publish pricing, what to watch, and how to set up a continuous monitor that surfaces rate changes within hours of publication, so your routing and forecasting can adjust before the next billing cycle.
Quick Setup
Pick a provider and optional model to preview per-token price-change alerts.
Why Monitor AI Provider Pricing
AI costs are typically the second or third largest infrastructure line for AI-native products. Same-day awareness of price changes affects routing, caching, and model-selection decisions in ways that compound monthly.
Per-Token Rate Cuts Affect Routing Decisions
When one provider cuts rates on a frontier model, teams running multi-provider routing can shift traffic the same day. A 20% per-token reduction on a model handling 30% of your traffic is a 6% cost reduction across the entire AI line, captured the day it ships.
New Model Tier Pricing Reshapes the Quality Curve
Providers regularly launch new tiers (mini, nano, ultra) at different price-quality points. New tiers often absorb volume from older models at lower cost. Same-day awareness lets teams evaluate routing changes before the next monthly bill.
Batch and Cache Discounts Materially Change Economics
Batch-mode pricing (typically 50% of synchronous) and prompt-caching discounts (often 75-90% off for cached tokens) materially change inference economics for many workloads. Provider rollouts of these features and adjustments to discount tiers are worth same-day awareness.
Free-Tier and Rate-Limit Changes
Free-tier adjustments and rate-limit increases affect dev and test patterns. For teams running heavy evaluation pipelines on free tiers, changes are operationally meaningful.
Context-Window Pricing Tiers
Pricing on long-context calls is sometimes tiered: the first N tokens at one rate, additional tokens at another. Changes to these tiers can swing cost on long-document or long-conversation use cases.
How AI Providers Publish Pricing
Each provider publishes pricing at a stable URL:
https://openai.com/api/pricing/
https://www.anthropic.com/pricing
https://ai.google.dev/pricing
https://aws.amazon.com/bedrock/pricing/
https://azure.microsoft.com/en-us/pricing/details/cognitive-services/openai-service/
https://mistral.ai/pricing
https://www.together.ai/pricing
https://replicate.com/pricingEach page renders the current per-token rates for every model in the provider's catalog. Most pages also include batch-mode pricing, cache pricing, fine-tuning pricing, and image/audio model pricing on the same page. Some providers (Bedrock, Azure) split pricing across multiple pages by model or region.
Comparing Monitoring Approaches
| Approach | Cost | Latency | Coverage | Best For |
|---|---|---|---|---|
| Manual page refresh | Free | Variable | Per-page effort | Awareness only |
| Provider newsletters | Free | Days | Major changes | Awareness |
| Artificial Analysis pricing tracker | Free | Daily | Curated set | Cross-provider comparison |
| Internal scraping | Free + engineering | Variable | Custom | Teams with engineering capacity |
| PageCrawl on pricing pages | Free tier to $80/year | Hours | Configurable per page | AI engineering, FinOps, product strategy |
For teams that already have a FinOps or platform monitor in place, PageCrawl lets you plug AI provider pricing into the same alert channel as cloud pricing, API changelogs, and other vendor signals. The integrated view supports faster cross-functional response.
Setting Up AI Pricing Monitoring in PageCrawl
Step 1: List the providers your workload uses
For most teams: OpenAI, Anthropic, Google AI, and Bedrock cover roughly 90% of production AI spend. Add Azure OpenAI if you use it. Add Mistral, Together, or Replicate for open-source-hosted workloads.
Step 2: Add provider pricing pages
Paste each provider pricing URL into PageCrawl as a content monitor. Use full-page text mode so table cells are captured. Pricing tables render as page content; content monitoring detects per-cell changes.
Step 3: Add specialty pricing pages
For Bedrock specifically, model pricing is split across multiple pages by foundation-model provider. Add the most relevant 2-3 (Anthropic on Bedrock, Mistral on Bedrock, etc.). For Azure, similar split by service.
Step 4: Daily checks
AI providers change pricing on their own cadence; daily checks catch updates in time for cost forecasting. For very active periods (around major model launches), hourly checks may catch cuts faster.
Step 5: Route to FinOps and AI engineering
Pricing changes should flow to both the team running the workload and the team responsible for cost. A #ai-pricing Slack channel with both FinOps and AI engineering subscribed produces the right cross-functional view.
Step 6: Configure AI summaries
PageCrawl's AI summaries describe pricing diffs in plain language: "gpt-4o input price reduced from $5.00 to $2.50 per million tokens; cached input now $1.25." This converts a multi-column table diff into a focused alert.
Worked Example: An AI-Native Product Team Setup
Take a product team running OpenAI, Anthropic, and Google AI in production with $50K/month total AI spend. The setup:
- Add 4 provider pricing pages: OpenAI, Anthropic, Google AI, Bedrock.
- Add 2 specialty pages: Anthropic-on-Bedrock, Mistral-on-Bedrock.
- Set daily checks across all 6.
- Route alerts to
#ai-pricingSlack channel with both AI engineering and FinOps subscribed. - Configure AI summaries to highlight specific models and tiers.
- Pair with our LLM benchmark leaderboard monitor so price-quality trade-offs are visible together.
Total cost: Standard plan at $80/year covers the 6 monitors with room to spare. For a team with $50K/month AI spend, the cost is rounding error against a single same-day routing change that captures a rate cut.
Patterns Worth Watching For
Per-token rate changes on models you currently use. The highest-impact signal. Same-day awareness lets routing logic adjust immediately.
New cheaper tiers. Mini, nano, or low-cost tiers may absorb volume from older models. Often launched at significantly lower per-token rates.
Batch processing discounts. Batch pricing changes (typically structured as a percentage of sync pricing) affect economics for non-real-time workloads.
Cache pricing changes. Prompt-caching discounts have been one of the most material cost-management features in 2024-2025. Changes to cache pricing tiers affect retrieval-heavy workloads.
Context window pricing tier changes. Long-context calls sometimes have tiered pricing; changes affect long-document use cases disproportionately.
Free-tier and rate-limit adjustments. Affect dev and test patterns. Worth tracking even if you do not currently rely on free tiers.
Fine-tuning and custom-model pricing. Sometimes split out from base inference pricing. Worth monitoring if you operate fine-tuned models in production.
New model launches with introductory pricing. New models sometimes launch with promotional rates that revert later; same-day awareness matters for budgeting.
Combining AI Pricing Monitoring With Other Signals
The full value of AI pricing monitoring shows up when you pair it with related AI-ecosystem data, including AI coding agent pricing and credit changes.
Combine with LLM benchmark leaderboards. Pair the pricing monitor with our LLM benchmark leaderboard monitor. Price-quality trade-offs become visible in a single alert stream.
Combine with SaaS API deprecation. Use our SaaS API deprecation monitor for the AI providers. Model deprecation timelines often accompany pricing-page updates.
Combine with cloud pricing changes. Pair with our AWS and GCP pricing monitor. Self-hosting decisions hinge on the interaction between provider API pricing and underlying compute costs.
Combine with Kubernetes and Docker releases. Our Kubernetes monitor and Docker Hub monitor cover the infrastructure layer for teams running open-source-model self-hosting workloads.
Use Cases
AI platform engineering. Pricing changes feed routing logic and model selection. Multi-provider routers benefit from same-day awareness across all providers.
FinOps. Daily price awareness supports accurate cost forecasting. For organizations with significant AI spend, this is a meaningful forecasting input.
Product management. Cost-per-task metrics shift with provider pricing changes. Product teams negotiating margin against AI inference cost benefit from same-day awareness.
AI consultancies. Client cost-optimization recommendations stay current. The pricing archive doubles as a longitudinal dataset for trend analysis and benchmarking.
Investor research. AI lab pricing trends are a useful signal for competitive analysis and unit-economics analysis of AI-native companies.
Procurement and vendor management. Enterprise contract negotiations benefit from same-day awareness of list-price changes; vendors offering enterprise discounts off list price are easier to negotiate when list price is moving.
Frequently Asked Questions
How often do AI providers change pricing? Variable. Major providers (OpenAI, Anthropic, Google) have changed pricing roughly monthly through 2024-2025, with some periods of more frequent updates around model launches. Specialty providers update less frequently.
Will PageCrawl detect changes inside model-specific tabs? PageCrawl captures the page as rendered. For pages with model-selector dropdowns, the default selection is captured; for per-model precision, use URL parameters that select the specific model directly.
Can I monitor enterprise pricing pages? Yes, with appropriate auth-header configuration for any vendor-portal pages. Public list pricing is the most-monitored target; enterprise contract pricing is typically not on a monitorable page.
What about per-region pricing? AWS Bedrock and Google Vertex have per-region pricing; the pages support region selection via URL parameters. For per-region tracking, build region-specific monitor URLs.
How do I avoid noise from cosmetic page changes? AI summaries distinguish substantive price changes from layout adjustments. For absolute precision, narrow the monitor to a CSS selector targeting the pricing table.
Do I need a paid plan? The Free plan supports 6 monitors at daily checks, enough for the major providers. Standard at $80/year covers a more extensive setup including specialty pages, region-specific tracking, and fine-tuning pricing.
Choosing your PageCrawl plan
PageCrawl's Free plan lets you monitor 6 pages with 220 checks per month, which is enough to validate the approach on your most critical pages. Most teams graduate to a paid plan once they see the value.
| Plan | Price | Pages | Checks / month | Frequency |
|---|---|---|---|---|
| Free | $0 | 6 | 220 | every 60 min |
| Standard | $8/mo or $80/yr | 100 | 15,000 | every 15 min |
| Enterprise | $30/mo or $300/yr | 500 | 100,000 | every 5 min |
| Ultimate | $99/mo or $999/yr | 1,000 | 100,000 | every 2 min |
Annual billing saves two months across every paid tier. Enterprise and Ultimate scale up to 100x if you need thousands of pages or multi-team access.
At an engineering hourly rate, Standard at $80/year pays for itself the first time you catch a breaking API change, a deprecated endpoint, or a silent config change before it takes down production. 100 monitored pages is enough to cover the changelogs and docs of every third-party API your stack depends on. Enterprise at $300/year adds higher check frequency, 500 pages, and full API access. All plans include the PageCrawl MCP Server, which plugs directly into Claude, Cursor, and other MCP-compatible tools. Developers can ask "what changed in the Stripe API docs this month?" and get a summary pulled from your own monitoring history. AI assistants can create monitors through conversation on every plan, including Free, turning your tracked pages into a living knowledge base instead of a pile of alert emails.
Getting Started
Add the OpenAI, Anthropic, Google, and Bedrock pricing pages to PageCrawl on a daily check. Create a free account and the next AI price change will arrive in your channel within hours of publication.
Once basic coverage is in place, expand to specialty pages, region-specific tracking, and pair with leaderboard and API deprecation monitors. The Standard plan at $80/year covers a serious AI-platform-engineering setup. For organizations with meaningful AI spend, the cost recovers itself the first time a same-day routing change captures a price cut before the next billing cycle.

