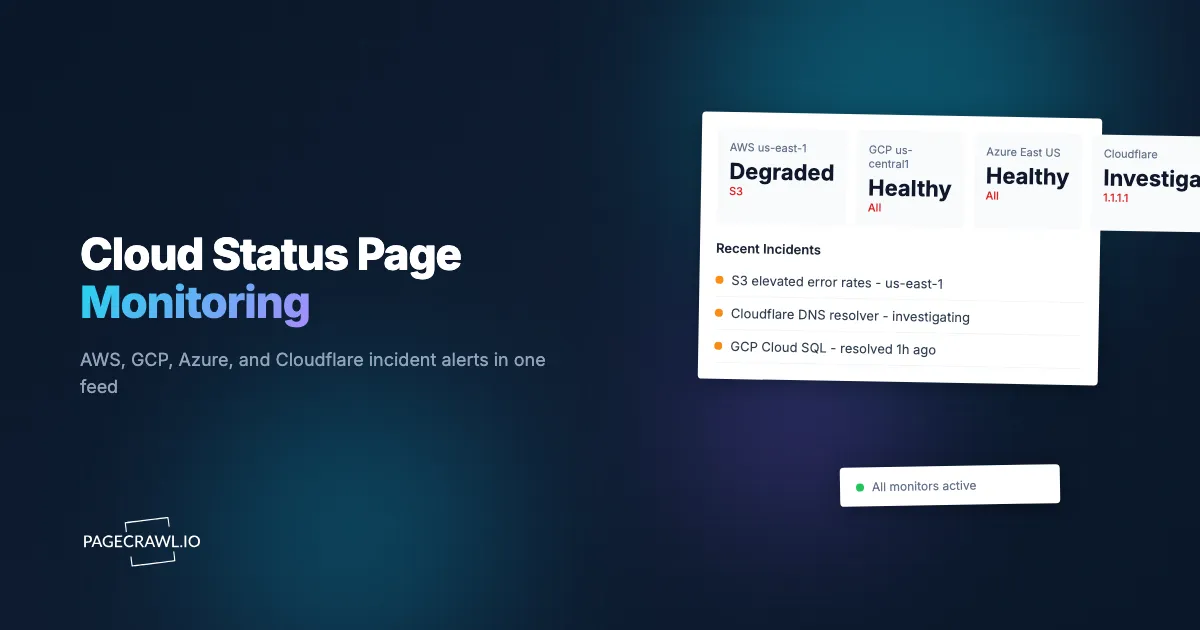
When us-east-1 had its major network device impairment incident in December 2021, the first reports on Twitter appeared 14 minutes before AWS's status page acknowledged the issue. The status page eventually turned red, and stayed red, for hours. Teams that were monitoring the status page directly saw the acknowledgment within seconds of the green-to-yellow flip. Teams that relied on AWS Health Dashboard email subscriptions saw it 20 minutes after that. By then, on-call engineers had been triaging customer-reported impact for the better part of an hour.
The first signal that a cloud provider is degraded is almost never the provider's own status page. Customer reports on Twitter, Hacker News, and Reddit routinely arrive 20-40 minutes before the official status banner flips from green to yellow. But once it does flip, you need to know within seconds, especially if the affected service is on the critical path of your application. The provider's own subscription mechanisms (AWS Health Dashboard, GCP RSS, Azure email) work, but they are coarse, lag the page update, and force you to triage which alerts are actually relevant to your stack.
This guide covers how AWS, GCP, Azure, and Cloudflare publish status, why their native subscriptions miss the mark, and how to set up a single cross-provider monitor that surfaces region-specific incidents within minutes of the official acknowledgment.
Quick Setup
Pick the providers and regions you depend on and preview incident alerts the moment they post.
Why Monitor Cloud Provider Status Pages Directly
Cloud provider native status pages do support email and RSS, but they suffer from well-known limitations that compound when you operate on multiple providers.
Subscription Granularity Is Coarse
Provider subscriptions are typically all-or-nothing per service. You can subscribe to every AWS service in every region, or to specific services that produce a noisy stream when you only care about your two regions. There is no clean middle ground. Page monitoring lets you filter at the alert layer.
Status Page Posts Lag the Actual Incident
Status updates often lag the actual incident by 20 or more minutes. The status page is the official acknowledgment, and acknowledgment is typically the last thing in the incident-response chain. Monitoring the page gives you the earliest unambiguous signal that the provider has acknowledged the issue.
Multi-Cloud Aggregation Is Painful
Teams running on two or three providers want one alert stream, not three different inboxes. A single PageCrawl folder containing AWS, GCP, Azure, and Cloudflare alerts produces a unified incident channel that matches how on-call rotations actually work.
History and Correlation Are Limited
Provider status pages do not retain long history. Monitoring them yourself builds a searchable archive of incidents that you can correlate against your own metrics, customer reports, and architectural reviews.
How Cloud Status Pages Are Published
Each major provider publishes a status URL with regional service breakdown:
https://health.aws.amazon.com/health/status
https://status.cloud.google.com/
https://azure.status.microsoft/en-us/status
https://www.cloudflarestatus.com/
https://status.digitalocean.com/
https://status.fastly.com/Each page renders the current state of every service by region. Most also expose RSS or JSON for individual services, though the RSS feeds often lag the page itself by minutes. The CloudFlare status page (Statuspage.io-hosted) is the most structured; AWS Health is the most fragmented.
For multi-cloud setups, the four major-provider pages plus your CDN and any specialty services (DataDog, Stripe, Twilio) cover roughly 95% of typical SaaS dependency surfaces.
Comparing Monitoring Approaches
| Approach | Cost | Latency | Cross-Provider | Best For |
|---|---|---|---|---|
| AWS Health Dashboard email | Free | 5-30 minutes after page update | AWS only | Pure-AWS shops |
| GCP RSS | Free | Variable | GCP only | Pure-GCP shops |
| StatusGator / IsDown | $50-300/month | Real-time | Multi-provider | Teams without engineering time |
| PagerDuty Status Pages | Subscription | Real-time | Configurable | Mature on-call programs |
| Internal RSS / scrapers | Free + engineering | Variable | Custom | Teams with engineering capacity |
| PageCrawl on status pages | Free tier to $80/year | 2-5 minutes | Configurable per page | Most teams, SRE rotations, multi-cloud |
StatusGator and IsDown are dedicated cross-provider status aggregators and are the right product for teams that want a turnkey solution at a higher price point. PageCrawl gives you the same kind of cross-provider coverage at lower cost, plus the option to plug status-page alerts into the same channel as your security, deployment, and API-change monitors.
Setting Up Cloud Status Monitoring in PageCrawl
Step 1: Identify the services and regions you actually use
Most teams use a small slice of each provider. Build a short list per cloud: AWS (EC2 us-east-1, S3 us-east-1, RDS us-east-1, CloudFront), GCP (Cloud Run us-central1, Cloud Storage, Firestore), Azure (App Service East US), Cloudflare (Workers, CDN). Make this list explicit before you build monitors.
Step 2: Add each provider's status page URL
For each cloud, add the main status page URL as a content monitor in PageCrawl. PageCrawl detects state changes in the rendered table on each page.
Step 3: Use AI summaries to filter by region
PageCrawl's AI change summaries can be tuned to focus on specific services or regions. This converts a page-wide change into a focused alert: "S3 us-east-1 elevated error rates (was Operational)." Without AI summaries, the raw diff against a multi-page provider status table is hard to read at glance.
Step 4: Set 2-minute checks for production paths
Cloud incidents are minute-sensitive. The Ultimate plan offers 2-minute checks; for most teams Standard at 15-minute checks is the right balance of cost and latency. If you have specific high-criticality dependencies, run Ultimate.
Step 5: Route to fast incident channels
PagerDuty webhook, Slack incident channel, or Opsgenie integration are the right targets for status-page alerts. The on-call rotation should see the alert within seconds of the page change. See our Slack alerts setup guide.
Step 6: Add upstream and downstream dependencies
Beyond the four big clouds, add Statuspage.io pages for the SaaS providers in your critical path: Stripe, Twilio, DataDog, Segment, Sentry, Auth0. A folder named dependencies-status with all of these covers most surprise-failure modes.
Worked Example: A Multi-Cloud SRE Setup
Take an SRE team supporting an application that uses AWS for compute, Cloudflare for CDN, and Stripe for payments. The setup:
- Add the AWS, Cloudflare, and Stripe status pages as three monitors.
- Add Cloud Run, GCP for any auxiliary services as a fourth.
- Set 2-minute checks (Ultimate plan) on all four, or 5-minute (Enterprise).
- Configure AI summaries to highlight services and regions:
us-east-1,Cloudflare Workers,Stripe API. - Route alerts to a PagerDuty incident-channel webhook.
- Configure Slack mirror to
#status-feedfor the broader team. - Add a
dependencies-statusfolder for the additional SaaS surfaces.
Total cost: Enterprise plan at $300/year covers the multi-cloud setup with 5-minute checks; Ultimate at $999/year drops latency to 2 minutes. For an SRE team protecting a production application, the cost is rounding error against the time saved on a single multi-hour incident.
Patterns Worth Watching For
Region-specific service degradation in the regions you operate. The vast majority of provider incidents are regional; same-day awareness is region-aware awareness.
Multi-region incidents that may indicate a control-plane problem. When a provider's API or console is degraded across regions, the underlying cause is usually different from a regional data-plane issue.
Dependent service incidents in upstream providers. A CDN incident that affects your origin, a CA incident that affects your TLS issuance, an identity provider incident that affects login.
Recovery status updates that confirm your monitoring graphs are accurate. The "resolved" post is as informative as the initial incident post, because it tells you the provider considers the issue closed.
Frequency clustering for a specific service. Multiple incidents on the same service within a quarter is an architectural signal worth raising in a postmortem or capacity review.
Lateness of disclosure. Some incidents are acknowledged only after customer pressure. Monitoring the page directly catches the acknowledgment the moment it lands, which can be informative on its own.
Combining Status Monitoring With Other Signals
The full value of status-page monitoring shows up when you pair it with other observability and security data.
Combine with CISA KEV. Pair the status monitor with our CISA KEV monitoring guide. Some provider incidents are coincident with newly disclosed CVEs in provider infrastructure.
Combine with SaaS API deprecation tracking. Use our SaaS API deprecation monitor for the same vendors. Status incidents and deprecation timelines together produce a complete vendor-reliability picture.
Combine with Kubernetes release feeds. Our Kubernetes CVE monitor tracks the orchestration layer; status pages cover the provider layer. Together they give a complete platform-reliability view.
Combine with cloud pricing changes. Pair with our AWS and GCP pricing alerts guide. Status incidents sometimes correlate with infrastructure changes that also affect pricing or quotas.
Use Cases
SRE and platform teams. Real-time cloud status alerts arrive before customer reports and inform incident communications. For teams running production on AWS, GCP, or Azure, this is the lowest-cost source of provider-side incident awareness.
Multi-cloud architectures. One PageCrawl folder covers AWS, GCP, Azure, and Cloudflare in a single alert stream. Multi-cloud teams that have been juggling multiple subscription mechanisms find the unified stream a real workflow improvement.
Customer support and ops. Same-minute awareness of upstream incidents helps prepare customer status communications before the support tickets arrive.
Architecture review. Historical monitoring of provider incidents builds a real picture of where your most-used services have struggled. Incident frequency by service-region is a useful input to architectural decisions.
Compliance and SLA reporting. Documented monitoring of upstream incidents supports SLA-related claims and credit calculations. For organizations that pass through cloud-provider SLAs to customers, this is direct evidence.
Vendor management. Status incidents feed into renewal conversations. A provider with frequent uncommunicated incidents is a procurement signal.
Frequently Asked Questions
How quickly does PageCrawl detect a status page change? At 2-minute checks (Ultimate), within 2 minutes of the page update. At 5-minute checks (Enterprise), within 5. The bottleneck is not detection but the provider's own time-to-publish.
Does this replace the provider's native subscription? No, but it typically reduces reliance on it. Many SREs run both: native subscription as backstop, PageCrawl for primary alerting with cross-provider unification.
What about RSS feeds? Most provider RSS feeds lag the page itself by several minutes. The page is the authoritative surface; monitoring the page directly gives the fastest signal.
Can I get separate alerts for separate services? PageCrawl alerts on any page change; AI summaries describe which service and region changed. For per-service routing, set up filtering downstream in your incident-routing system.
Will I get noise from minor status-message edits? AI summaries help distinguish a status-icon change (operational to degraded) from a minor message edit. Most teams find the signal-to-noise acceptable with default settings.
Do I need Ultimate for cloud status monitoring? Only if minute-level latency is critical. Many production teams run Enterprise at 5-minute checks; the additional 3 minutes rarely materially changes incident response.
Choosing your PageCrawl plan
PageCrawl's Free plan lets you monitor 6 pages with 220 checks per month, which is enough to validate the approach on your most critical pages. Most teams graduate to a paid plan once they see the value.
| Plan | Price | Pages | Checks / month | Frequency |
|---|---|---|---|---|
| Free | $0 | 6 | 220 | every 60 min |
| Standard | $8/mo or $80/yr | 100 | 15,000 | every 15 min |
| Enterprise | $30/mo or $300/yr | 500 | 100,000 | every 5 min |
| Ultimate | $99/mo or $999/yr | 1,000 | 100,000 | every 2 min |
Annual billing saves two months across every paid tier. Enterprise and Ultimate scale up to 100x if you need thousands of pages or multi-team access.
At an engineering hourly rate, Standard at $80/year pays for itself the first time you catch a breaking API change, a deprecated endpoint, or a silent config change before it takes down production. 100 monitored pages is enough to cover the changelogs and docs of every third-party API your stack depends on. Enterprise at $300/year adds higher check frequency, 500 pages, and full API access. All plans include the PageCrawl MCP Server, which plugs directly into Claude, Cursor, and other MCP-compatible tools. Developers can ask "what changed in the Stripe API docs this month?" and get a summary pulled from your own monitoring history. AI assistants can create monitors through conversation on every plan, including Free, turning your tracked pages into a living knowledge base instead of a pile of alert emails.
Getting Started
Add the four major cloud provider status URLs to PageCrawl on a 5-minute schedule. Create a free account, route alerts to your incident channel, and the next cloud incident will arrive in your channel within minutes of the provider posting.
Once basic cross-provider coverage is in place, expand to upstream SaaS dependencies (Stripe, Twilio, DataDog, Auth0) and any specialty providers in your critical path. The Enterprise plan at $300/year covers a serious multi-cloud setup; Ultimate at $999/year drops latency further for teams where seconds matter. For SRE teams running production on multiple providers, the cost is the cheapest line item on the observability bill.