XPath selectors are powerful tools that help you identify and extract specific elements on a web page. In this guide, we'll explore common XPath selectors that you can use when monitoring websites for changes to make your web monitoring efforts more effective.
Why Not CSS Selector?
CSS Selectors are favored by many web developers as they are easy to learn if you already know CSS syntax. On the other hand, XPath Selectors offer greater power and flexibility, such as the ability to find elements that contain specific text. However, the learning curve for XPath can be steeper. If you already know CSS - that's good, you should be able to use it for most use cases. If you don't know any, we recommend starting with XPath, since it can be more flexible.
XPath Cheat sheet
Here, you'll find a convenient 'cheat sheet' that comprehensively covers the most commonly used XPath selectors for your reference. We suggest taking a quick look through this list before proceeding to the Common XPath Selectors for Web Monitoring section below.
HTML Basics
Before we start, you should familiarize yourself with some fundamental concepts to better understand the terminology and functionality. Here are a few key terms:
Attribute: An attribute provides additional information about an HTML element. It is always specified in the start tag of an element and usually comes in name/value pairs like
name="value". For example, in<a href="https://example.com">,hrefis an attribute name andhttps://example.comis its value.Element: An HTML element is an individual component of an HTML document or web page. It is written with a start tag, with an optional end tag, and content in between. For example,
<p>This is a paragraph</p>; here,<p>is the start tag,</p>is the end tag, andThis is a paragraphis the content.ID: The
idattribute is used to specify a unique id for an HTML element. You cannot have more than one element with the same id in an HTML document. It is used for identifying and targeting the element with CSS and JavaScript. For example,<div id="header">defines a division with a unique id ofheader.Class: The
classattribute is used for specifying a class name for an HTML element. Unlike theidattribute, the same class can be used on multiple elements. This is useful for applying the same styling or behavior to different elements. For example,<span class="highlight">assigns thehighlightclass to a span element, which can be targeted with CSS or JavaScript.
How to test the selector?
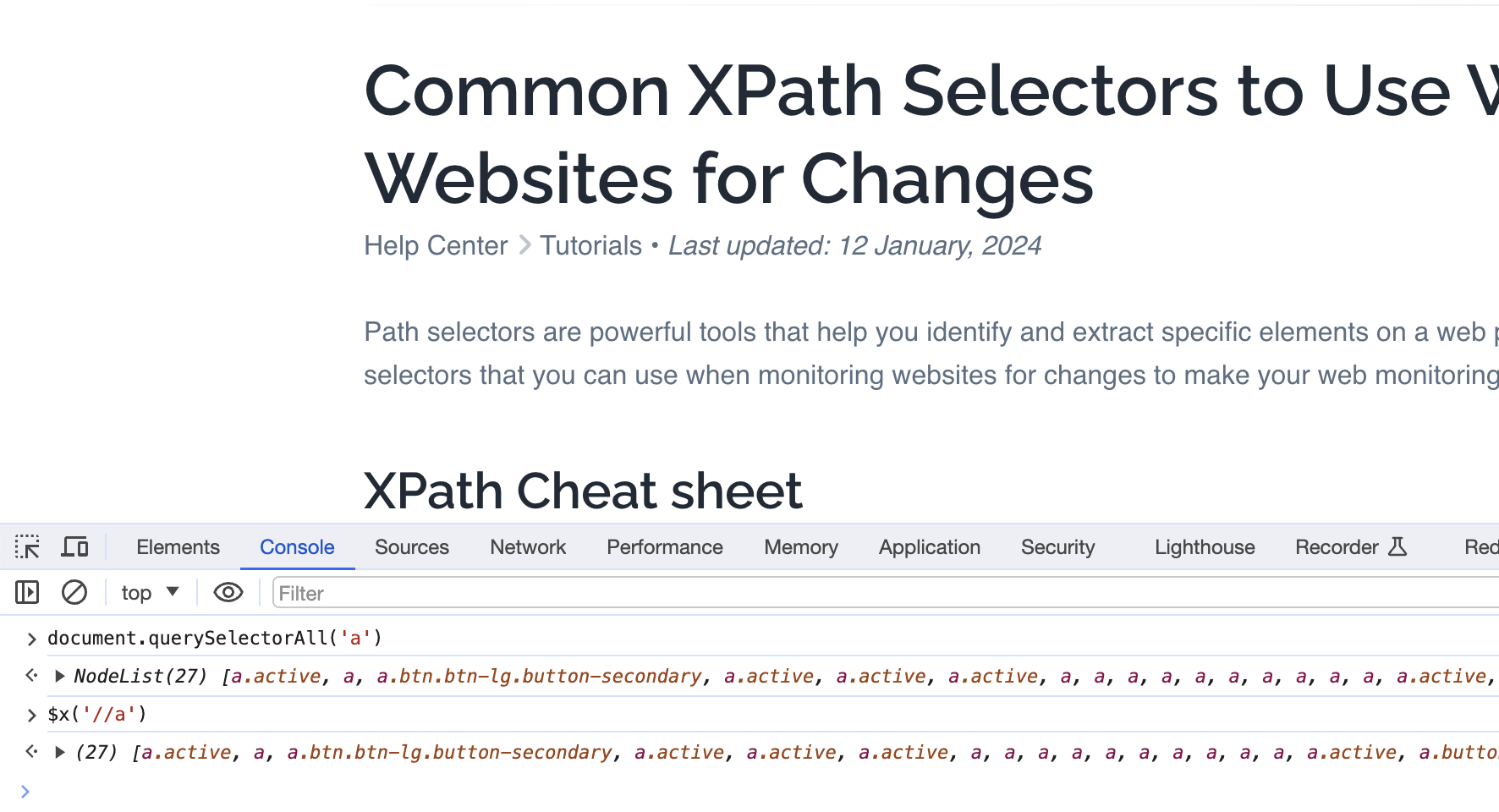
You might wonder where you can try the selector before pasting it in PageCrawl.io You should open browser console and use following commands to test your selector.
XPath
$x('//a')CSS
document.querySelectorAll('a')XPath Selector Basics
//: Selects all matching elements anywhere in the document./: Selects from the root element.element: Selects elements with the specified name.[@attribute]: Selects elements with the specified attribute.
Advanced XPath Selectors
[@attribute='value']: Selects elements with a specific attribute value.[@attribute!='value']: Selects elements with an attribute value not equal to 'value'.[starts-with(@attribute,'prefix')]: Selects elements with an attribute starting with 'prefix'.[substring(@attribute, string-length(@attribute) - string-length('suffix') + 1) = 'suffix']: Selects elements with an attribute ending with 'suffix'. Note: there is no directends-with()function in XPath 1.0, so this workaround is needed.[contains(@attribute,'substring')]: Selects elements with an attribute containing 'substring'.[@attribute1='value1' and @attribute2='value2']: Selects elements that meet multiple attribute conditions.[@attribute1='value1' or @attribute2='value2']: Selects elements that meet at least one of the attribute conditions.not(expression): Negates a condition.
Text and Content Selection
text(): Selects the text content of an element.contains(text(),'substring'): Selects elements containing specific text.starts-with(text(),'prefix'): Selects elements with text starting with 'prefix'.substring(text(), string-length(text()) - string-length('suffix') + 1) = 'suffix': Selects elements with text ending with 'suffix'. Note:ends-with()is an XPath 2.0 function and is NOT supported in browsers (which only support XPath 1.0). Use thissubstring()workaround instead.
Navigation and Hierarchy
/parent::element: Selects the parent of the current element./child::element: Selects the children of the current element./ancestor::element: Selects ancestors of the current element./descendant::element: Selects descendants of the current element.[position()=1]: Selects the first matching element.[last()]: Selects the last matching element.[position()>2]: Selects elements after the first two.
Wildcards and Dynamic Selection
*: Selects all elements.element[*]: Selects elements with at least one child element.element[@*]: Selects elements with at least one attribute.element[contains(@attribute,'value')]: Selects elements with attributes containing 'value'.
Functions
count(expression): Counts the number of matching elements.sum(expression): Sums numeric values within matching elements.concat(string1, string2): Combines two strings.substring(string, start, length): Extracts a substring.normalize-space(string): Removes leading/trailing spaces and collapses internal spaces.
Common XPath Selectors for Web Monitoring
Here are some common XPath selectors that you can employ when monitoring websites for changes. Initially, basic XPath selectors will be covered, and we will then proceed to more advanced examples.
1. Selecting Text
XPath allows you to target specific text elements on a webpage, which is useful for tracking changes in content, headlines, or paragraphs. For example:
//h1 // Selects all h1 headers on the page.
//p // Selects all paragraph elements.
//div[@class='content'] // Selects text within div elements with a specific class.2. Tracking Links
XPath selectors help you monitor links, whether you want to track all links on a page, external links, or links with specific text. For instance:
//a[@href] // Selects all links with an href attribute.
//@href[not(contains(.,'example.com'))] // Selects external links (replace 'example.com' with the target domain).
//a[contains(text(),'Download')] // Selects links with specific anchor text, case-sensitive.To view more examples with links, visit Tracking links with text tutorial.
3. Checking Images
To monitor images on a webpage, you can use XPath selectors to identify images by their source (src) attribute or alt text. For example:
//img // Selects all image elements.
//img/@src // Selects the src attribute of all images.
//img[contains(@alt,'logo')] // Selects images with specific alt text.4. Handling Tables
XPath selectors are particularly useful for extracting data from tables, which are commonly used on websites for displaying structured information. For example:
//table // Selects all tables on the page.
//table//tr // Selects all table rows.
//table//tr/td[2] // Selects the second column (td) in all rows.5. Monitoring Specific Elements
You can target elements with specific attributes or attributes containing certain values using XPath selectors. For instance:
//*[@id='specificId'] // Selects elements with a specific ID attribute.
//*[@class='highlight'] // Selects elements with a specific class attribute.6. Monitoring Elements where Text contains in Class or ID
To monitor elements when their class or ID contains a part of text, you can use XPath selectors with the contains() function. For example:
//*[contains(@class, 'partial-text')] // Selects elements with a class containing 'partial-text'.
//*[contains(@id, 'partial-text')] // Selects elements with an ID containing 'partial-text'.
//input[starts-with(@name, 'user_')] // Selects input elements with names starting with 'user_'.
//input[contains(@id, 'search')] // Selects input elements with IDs containing 'search'.
//button[contains(@class, 'btn-')] // Selects buttons with class names containing 'btn-'.
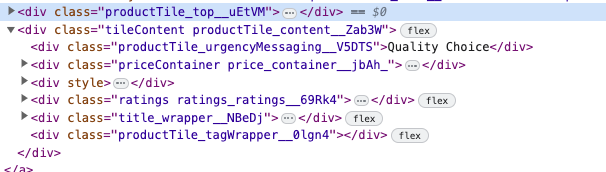
This XPath selector is particularly valuable, especially when dealing with CSS classes that include unpredictable or random text fragments.
For instance, suppose you want to extract the text 'Quality Choice' from an image, as shown in the example above. However, the CSS class, such as productTile_urgencyMessaging__V5DTS includes a suffix like __V5DTS that is prone to change with each website update.
To avoid having to update the selector each time website updates, you may employ the XPath contains() function to select an element.
//*[contains(@class, 'productTile_urgencyMessaging')] // Retrieve 'Quality Choice' text7. Using Logical Operators
XPath supports logical operators for combining conditions. This is particularly useful for complex selections. For example:
//a[@class='external' or @class='external-link'] // Selects links with class 'external' or 'external-link'.
//div[@class='important' and contains(text(),'Alert')] // Selects divs with class 'important' containing 'Alert'.
8. Complex Expressions
You can create complex XPath expressions by combining multiple conditions and functions. This provides immense flexibility in your selections. For example:
//div[@class='content' and (contains(text(),'Important') or contains(text(),'Alert'))]
//table[not(@class='hidden')]/tbody/tr[td[2]='Completed']/td[3]
Using XPath Selectors in PageCrawl.io
To leverage these advanced XPath selectors effectively for website monitoring, you can integrate them with web monitoring tools such as PageCrawl.io:
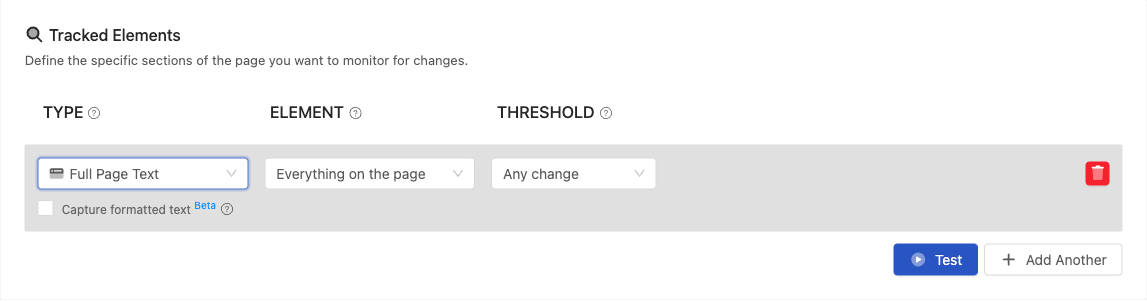
- Log in to your PageCrawl account.
- Click on Track New Page, fill in the page URL then select Tracked Elements to track.
- Select "Text" as tracked element and then specifying XPath selector to track.
- Save & start monitoring page for changes.